目次
概要
- RedshiftからS3にファイル配置と取得を行います。
- AWSのサンプルテーブルを使用します。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c_sampledb.html
ロールを作成しredshiftに関連付ける
ロールを作成し、redshiftとの関連付けが必要です。
1.最初にロールを作成します。IAMの画面に遷移します。
2.ロールを作成します。信頼されたエンティティタイプはAWSのサービスを選択します。
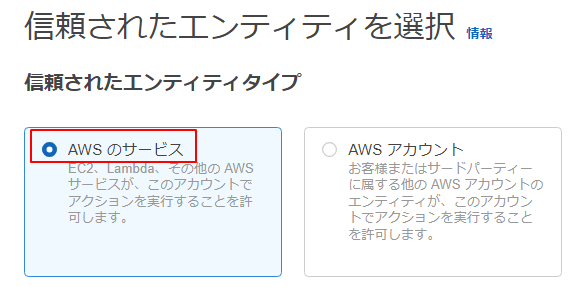
3.ユースケースは、RedshiftのCustomizableを選択します。
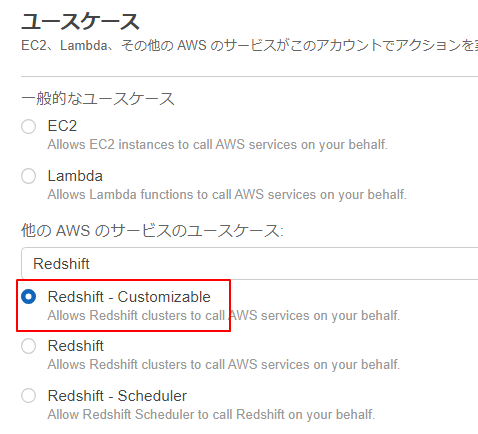
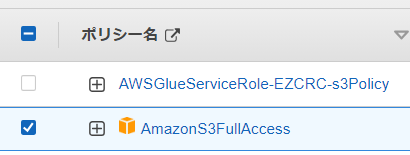
4.S3に関するポリシーを追加します。
5.ロール名を入力してロールを作成します。redshift-s3-role

6.次は作成したロールをredshiftに紐づけます。
redshiftの画面に遷移し、クラスターのリンクをクリックします。
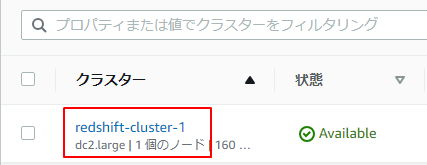
7.プロパティからIAMロールを関連付けるをクリックします。
作成したロールを選択します。
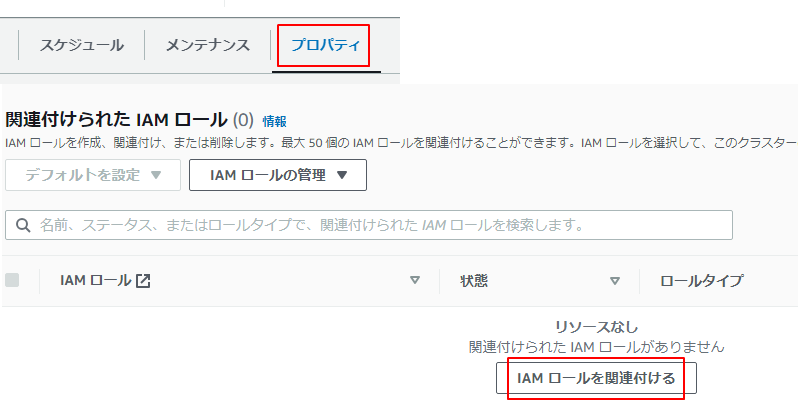
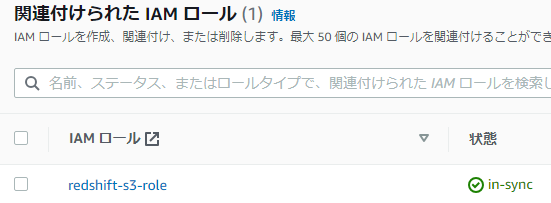
8.完了すると状態はin-syncになります。
redshiftのテーブルのデータをcsvファイルとしてs3に配置(unload)
1.redshiftの画面に遷移してクエリエディタから以下を実行します。
unload ('select * from category')
to 's3://test-data-s3-bk/test_category'
iam_role 'arn:aws:iam::111111111111:role/redshift-s3-role'
header
format csv
parallel off
allowoverwrite;
1行目でselect文を実行し、その結果を2行目のs3に配置します。
5行目は、CSV形式で出力されます。
6行目は、ファイルが1つになります。
7行目は、上書き可能になります。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_UNLOAD_command_examples.html
エスケープ
※whereの条件を指定する時等の値をシングルコーテーションで括る場合は、エスケープとしてシングルコーテーションの前にシングルコーテーションを付けます。
unload ('select * from category where catgroup = ''Sports''')
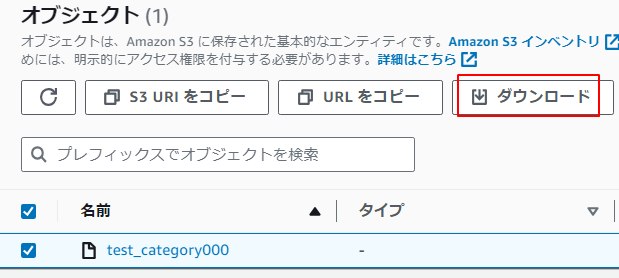
2.成功すると以下のようにS3に配置されます。ダウンロード可能です。
S3にあるファイルをredshiftのテーブルに取り込む(copy)
上記でS3に出力したcategoryのデータをテストとして作成するcategory_testテーブルに取り込みます。
1.categoryテーブルからcategory_testテーブルを作成します。
CREATE TABLE public.category_test (
catid smallint NOT NULL ENCODE raw
distkey
,
catgroup character varying(10) ENCODE lzo,
catname character varying(10) ENCODE lzo,
catdesc character varying(50) ENCODE lzo
) DISTSTYLE KEY
SORTKEY
(catid);
2.以下のcopyコマンドを実行するとs3のcsvのデータが、redshiftのcategory_testテーブルに登録されます。
copy category_test from 's3://test-data-s3-bk/test_category000' csv
iam_role 'arn:aws:iam::111111111111:role/redshift-s3-role'
region 'ap-northeast-1'
ignoreheader 1;
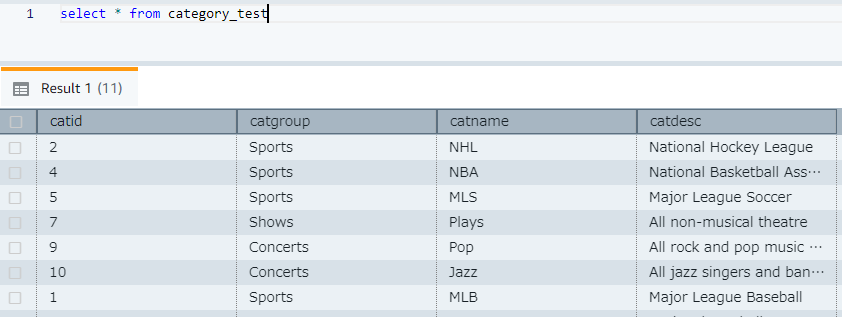
3.以下のようにデータが登録されていることを確認できました。
関連の記事