JavaのcodePointAtメソッドで、文字からUnicodeコードポイントを取得するサンプルです。
目次
| サンプル | codePointAtとは |
| Unicodeコードポイントを取得する | |
| 数値文字参照 | |
| サロゲートペア文字列の場合 |
codePointAtとは
| public int codePointAt(位置) |
- 文字列のうち、引数の数値の位置にあるUnicodeコードポイントを返します。
- 文字列の最初の1文字目の位置は0です。
- 引数が範囲外のときは、IndexOutOfBoundsExceptionの例外を返します。
- Java1.5で導入されました。
- 以下はOracleのJava8のcodePointAtメソッドのリンクです。
https://docs.oracle.com/javase/jp/8/docs/api/java/lang/String.html#codePointAt-int-
Unicodeコードポイントを取得する
package test1;
public class Test1 {
public static void main(String[] args) {
String a = "ABあい";
System.out.println(a.codePointAt(0)); // 65
System.out.println(a.codePointAt(1)); // 66
System.out.println(a.codePointAt(2)); // 12354
System.out.println(a.codePointAt(a.length()-1)); //12356
System.out.println
(Integer.toHexString(a.codePointAt(0))); //41
System.out.println
(Integer.toHexString(a.codePointAt(1))); //42
System.out.println
(Integer.toHexString(a.codePointAt(2))); //3042
}
}8行目は「A」を指しUnicodeコードポイントの65を表示します。
9行目は「B」を指しUnicodeコードポイントの66を表示します。
10行目は「あ」を指しUnicodeコードポイントの12354を表示します。
11行目は、最後の文字の「い」を指しています。lengthで文字列の長さを取得して1引きます。
Unicodeコードポイントの12356を表示します。
13~18行目は、toHexStringメソッドで16進数にしています。
数値文字参照
| 10進数の場合: &#数値; |
| 16進数の場合: &#x数値; |
上記コードの値は、数値文字参照で使用できます。
HTML上で
10進数の「A」と16進数の「A」は、「A」と表示されます。
10進数の「あ」と16進数の「あ」は、「あ」と表示されます。
サロゲートペア文字列の場合
サロゲートペア文字列の場合のサンプルです。
6行目は、サロゲートペアの「つちよし」です。
package test1;
public class Test1 {
public static void main(String[] args) {
String a = "𠮷";
System.out.println(a.codePointAt(0)); // 134071
System.out.println
(Integer.toHexString(a.codePointAt(0))); //20bb7
}
}8行目は、codePointAtメソッドで「つちよし」のUnicodeコードポイントを表示しています。
10行目は、toHexStringメソッドで16進数にしています。
文字コードは秀丸やサクラエディタで確認できます。
秀丸で見た場合
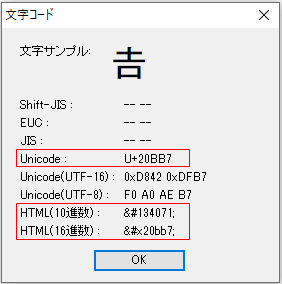
Unicodeコードポイントは、U+16進数で記述されます。
関連の記事