Oracleの実行計画の見方のサンプルです。
(確認環境:SQL Developer 21/19)
目次
| サンプル | テストデータの準備 |
| フルスキャン | |
| INDEX RANGE SCAN | |
| Bツリーインデックスのイメージ | |
| INDEX UNIQUE SCAN | |
| NESTED LOOPS | |
| HASH JOIN |
テストデータの準備
以下のテーブルがあるとします。件数は100万件です。
CREATE TABLE employee_data(
id NUMBER(7,0),
name VARCHAR2(20) not null,
romaji VARCHAR2(20),
primary key(id)
);| id | name | romaji |
|---|---|---|
| 1 | 86VL1 | 3AOG5 |
| 2 | YCPZ5 | P3S0C |
| ・・・ |
idは、プライマリーキー(PK)です。
nameはnot null制約がついています。
テストデータを100万件作成
BEGIN
FOR i IN 1..1000000 LOOP
INSERT INTO employee_data VALUES(i,dbms_random.string('x',5),dbms_random.string('x',5));
END LOOP;
COMMIT;
END;
/idは1から100万までの連番がセットされます。
nameとromajiはランダムの5文字がセットされます。
Oracle SQL Developerで実行計画を取得します。
Oracle SQL Developerで実行計画を確認する方法
フルスキャン
1.インデックスがない項目の値を指定して検索します。
select * from employee_data where name = 'WUP7E'2.DBMS_XPLANをクリックします。
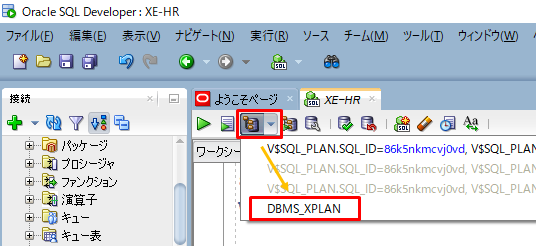
3.表示されたSQLを実行します。
select * from table
(dbms_xplan.display_cursor(sql_id=>'79wv5gh9w4zwg', format=>'ALLSTATS LAST'));4.実行結果が表示されます。
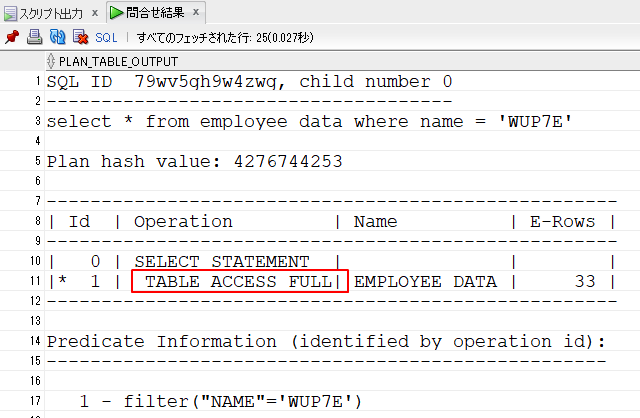
11行目は、「TABLE ACCESS FULL」で全件検索しています。where句にインデックスがない項目を指定したためです。
INDEX RANGE SCAN
1.テーブルの項目のNameにインデックスを作成します。
CREATE INDEX employee_data_idx1
On employee_data(name);デフォルトはBツリーインデックスが作成されます。
2.インデックスを設定した列を指定して検索します。
select * from employee_data where name = '87VIU'3.DBMS_XPLANをクリックします。
4.表示されたSQLを実行します。
select * from table
(dbms_xplan.display_cursor(sql_id=>'03yt8p8bd4dqn', format=>'ALLSTATS LAST'));4.実行結果が表示されます。
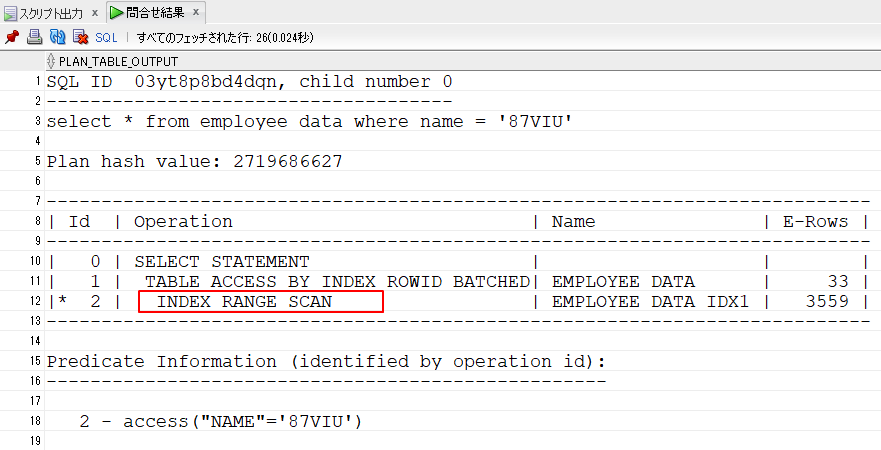
12行目は、「INDEX RANGE SCAN」をしています。
NAME列の値は一意ではないので範囲(RANGE SCAN)になりました。
11行目は、取得したROWIDでEMPLOYEE_DATAにアクセスしています。
Bツリーインデックスのイメージ
以下は、Bツリーインデックス(B+Tree)のイメージです。

数値が1から1500まである場合で、300を探す場合、一番上の500より小さいので左下に行き、150より大きいので右下に行き300を見つけます。
ポイントは、全件検索しなくて良くなることです。
B-Treeは、形が木に似ているので木構造とも呼ばれます。
指定された値でソートして格納されます。
件数が多いデータから数件のデータを取得するときに効果が出ます。
カーディナリティが高い場合、B-Treeインデックスを設定します。
→カーディナリティとは値の種類が多いことです。
→カーディナリティが低い場合(性別の男女等)、Bitmapインデックスを設定します。
インデックスの列がwhere句やテーブル結合の条件で使用されてはじめて機能します。
インデックスがある列のデータが更新されると、インデックスも更新されます。
→検索は早いが更新は遅いという状態になります。
INDEX UNIQUE SCAN
1.where句で主キーの値を指定して検索します。
select * from employee_data where id = '34225'2.DBMS_XPLANをクリックします。
3.表示されたSQLを実行します。
select * from table
(dbms_xplan.display_cursor(sql_id=>'4gj1qrzg0sjr5', format=>'ALLSTATS LAST'));4.実行結果が表示されます。
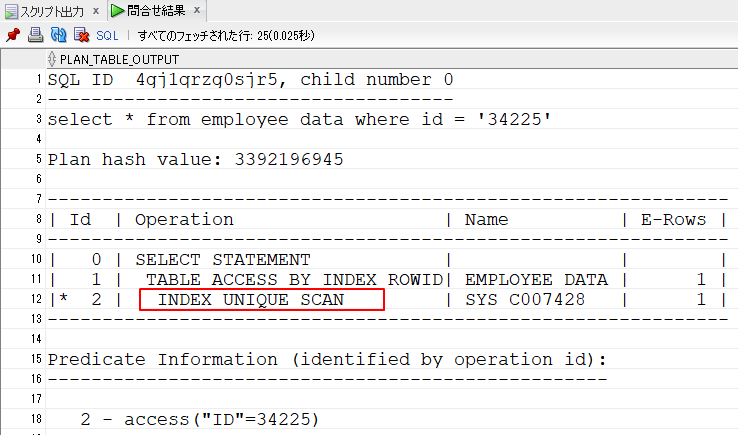
12行目は、「INDEX UNIQUE SCAN」をしています。
ID列の値は主キーで重複がないため一意(UNIQUE SCAN)になりました。
11行目は、取得したROWIDでEMPLOYEE_DATAにアクセスしています。
NESTED LOOPS
1.テーブルをinner joinで結合します。
employee_data2はemployee_dataと同じ構造で100件データがあります。
テーブルの結合は、PKのidで行っています。
select
e1.id,
e2.name
from employee_data e1
inner join employee_data2 e2
on
e1.id = e2.id;2.DBMS_XPLANをクリックします。
3.表示されたSQLを実行します。
select * from table
(dbms_xplan.display_cursor(sql_id=>'3kyz57m37ssvk', format=>'ALLSTATS LAST'));4.実行結果が表示されます。
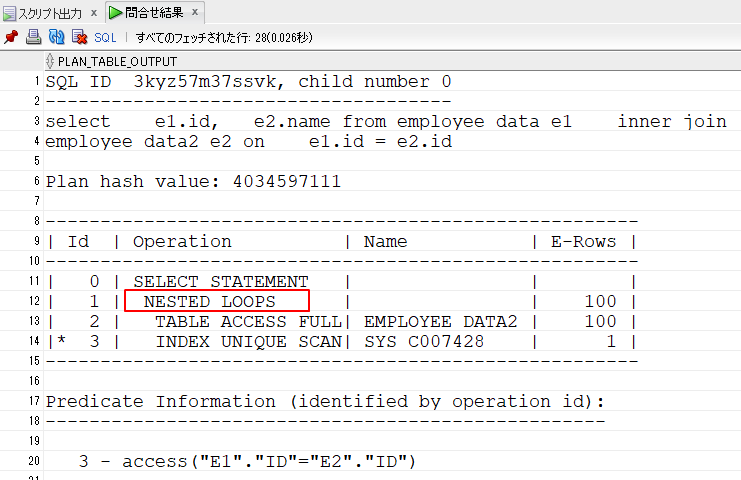
13行目は、「TABLE ACCESS FULL」で全件検索しています。
14行目は、「INDEX UNIQUE SCAN」をしています。
12行目は、13,14行目で取得したレコードをNESTED LOOPSで結合しています。
HASH JOIN
1.テーブルをinner joinで結合します。
employee_data2はemployee_dataと同じ構造で100件データがあります。
テーブルの結合は、nameで行っています。
select
e1.id,
e2.name
from employee_data e1
inner join employee_data2 e2
on
e1.name = e2.name;※INDEX RANGE SCANでemployee_dataに追加したindexは削除済みです。
2.DBMS_XPLANをクリックします。
3.表示されたSQLを実行します。
select * from table
(dbms_xplan.display_cursor(sql_id=>'gg83r3wrp6ank', format=>'ALLSTATS LAST'));4.実行結果が表示されます。
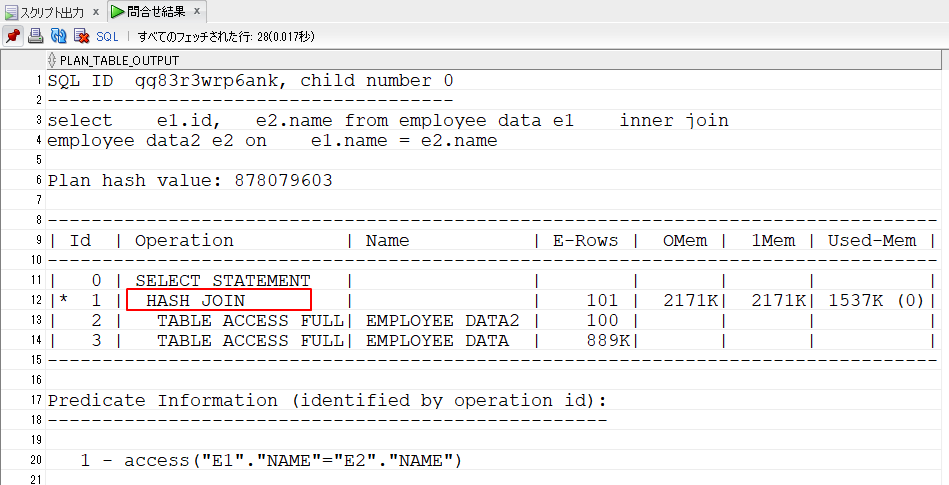
13行目は、「TABLE ACCESS FULL」EMPLOYEE_DATA2を全件検索しています。
14行目は、「TABLE ACCESS FULL」EMPLOYEE_DATAを全件検索しています。
12行目は、「HASH JOIN」しています。
関連の記事